 Tech-Connect Tech-Connect est un site web proposant des actualités, des tutoriels, des astuces et un forum dans le domaine technologique, informatique, science, télécommunications, mobile, tablette, windows, mac os, linux, opensource, android et IOS.
Tech-Connect Tech-Connect est un site web proposant des actualités, des tutoriels, des astuces et un forum dans le domaine technologique, informatique, science, télécommunications, mobile, tablette, windows, mac os, linux, opensource, android et IOS. 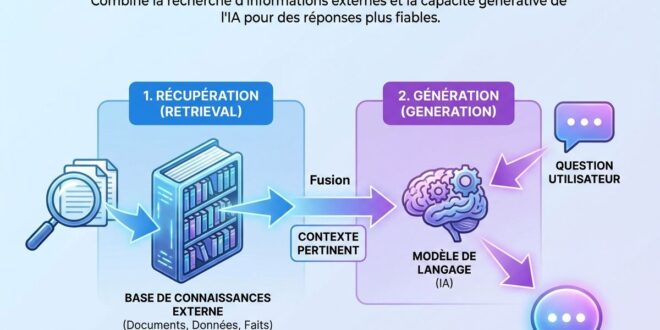
Vous avez déjà posé une question à ChatGPT, Claude ou Gemini et obtenu une réponse qui semblait parfaitement confiante… mais qui était complètement fausse ? Ou vous vous êtes demandé pourquoi votre IA préférée ne connaît pas les actualités d’hier, les prix actuels d’un produit, ou le contenu de vos propres documents internes ? Ce problème a un nom dans le monde de l’intelligence artificielle : les hallucinations et la date de coupure.
Et ce problème a une solution élégante qui est devenue en 2026 la technique la plus utilisée pour rendre les IA utiles dans des contextes réels : le RAG. RAG signifie Retrieval-Augmented Generation, qu’on pourrait traduire librement par « génération augmentée par la recherche ». C’est un terme technique qui cache une idée finalement très simple, si simple qu’on va l’expliquer avec une analogie en moins de trente secondes.
Imaginez un médecin brillant, formé dans les meilleures universités. Sa mémoire est vaste, ses connaissances profondes. Mais son diplôme date de 2023. Si vous lui demandez les dernières recommandations de l’OMS sur un médicament publié en 2025, il répondra du mieux qu’il peut… avec des informations potentiellement obsolètes. Maintenant, imaginez que ce même médecin ait accès à une bibliothèque de référence qu’il peut consulter en temps réel avant de vous répondre. Voilà ce qu’est le RAG.
Le problème que le RAG résout : pourquoi les IA « hallucinent » et vieillissent
Pour comprendre l’intérêt du RAG, il faut d’abord comprendre comment fonctionnent les grands modèles de langage (LLM : Large Language Models) comme ChatGPT, Claude, Gemini ou Mistral. Ces modèles ont été entraînés sur des quantités astronomiques de textes : livres, articles Wikipedia, pages web, forums, publications scientifiques… Le résultat de cet entraînement, c’est un modèle qui a « absorbé » implicitement une quantité colossale de connaissances dans ses paramètres, les milliards de chiffres qui composent le modèle.
Mais cet entraînement a une date de fin. On appelle ça la « date de coupure » (cutoff date). Après cette date, le modèle ne sait plus rien de ce qui s’est passé dans le monde. Un modèle entraîné jusqu’en décembre 2024 ne connaît pas les événements de 2025. Il ne connaît pas vos documents internes d’entreprise. Il ne connaît pas les prix de votre catalogue produit. Il ne connaît pas les nouvelles réglementations publiées ce mois-ci.
Deuxième problème : les hallucinations. Quand un LLM ne connaît pas la réponse à une question, il ne dit pas « je ne sais pas ». Il génère quelque chose qui ressemble à une réponse vraisemblable en interpolant entre les informations qu’il a appris. Parfois c’est correct. Parfois c’est faux mais présenté avec une confiance absolue. Dans des domaines critiques comme la médecine, le droit ou la finance, ce comportement est potentiellement dangereux.
📊 Les chiffres parlent d’eux-mêmes : selon les études de 2026 sur les systèmes RAG, l’ajout d’un système de récupération documentaire réduit les hallucinations de 40 à 70% par rapport à un LLM utilisé seul. Ce n’est pas une amélioration marginale, c’est une transformation qualitative.
📌 Hallucination IA : Quand un modèle de langage génère une information fausse mais présentée avec confiance, comme si elle était vraie. Exemple : inventer un livre qui n’existe pas, attribuer une citation erronée, ou citer une loi inexistante.
📌 Date de coupure (Cutoff date) : La date à laquelle s’est terminé l’entraînement d’un modèle IA. Après cette date, le modèle n’a aucune connaissance des événements survenus dans le monde réel.
Le RAG expliqué avec une analogie concrète
Voici l’analogie la plus claire pour comprendre le RAG, adaptée à n’importe quel niveau de connaissance technique.
🎓 L’étudiant sans livre vs l’étudiant avec une bibliothèque
Imaginez deux étudiants qui passent un examen de droit sur les nouvelles réglementations européennes de 2026.
Le premier étudiant, appelons-le l’IA classique, a passé des années à mémoriser des milliers de livres de droit jusqu’en 2024. Sa mémoire est prodigieuse. Mais les nouvelles réglementations de 2025 et 2026 ? Il n’en a jamais entendu parler. Face à une question sur ces nouvelles règles, il va répondre du mieux qu’il peut en extrapolant à partir de ce qu’il connaît avec un risque élevé de se tromper.
Le deuxième étudiant, l’IA avec RAG, a le même niveau de base. Mais avant de répondre à chaque question, il consulte un classeur mis à jour quotidiennement qui contient toutes les nouvelles réglementations. Il ne mémorise pas tout. Il cherche ce qui est pertinent, le lit rapidement, puis formule sa réponse en s’appuyant sur ce qu’il vient de trouver. Sa réponse est ancrée dans des faits vérifiables et récents.
📚 C’est exactement comme un assistant humain qui, avant de vous répondre sur un sujet complexe, dit : « Attendez, je vérifie dans la documentation » plutôt que de répondre de mémoire et risquer de se tromper.
🔍 L’examen oral avec aide-mémoire
Autre façon de voir les choses. Imaginez un examen oral en deux versions. Version 1 (LLM classique) : vous répondez uniquement de mémoire. Version 2 (RAG) : vous pouvez consulter un classeur de fiches pendant l’examen. Mais attention, vous ne lisez pas les fiches au hasard. Avant chaque réponse, le système sélectionne automatiquement les deux ou trois fiches les plus pertinentes pour cette question précise, et vous les donne à lire en quelques millisecondes. Vous formulez ensuite votre réponse en vous appuyant sur ces fiches. C’est le RAG.
Comment fonctionne le RAG techniquement
Maintenant qu’on a l’intuition, rentrons un peu dans la mécanique. Ça se passe en deux grandes phases : la préparation (indexation) et l’utilisation (requête).
Phase 1 : La préparation pour constituer la bibliothèque
Avant de pouvoir répondre à des questions, le système RAG doit préparer sa base de connaissances. Voici les étapes :
Étape 1 : Collecte des documents : On rassemble tous les documents que l’IA devra pouvoir consulter : PDFs, pages web, emails, bases de données, wikis internes, manuels produits…
Étape 2 : Découpage en morceaux (chunking) : Chaque document est découpé en petits morceaux de texte, appelés « chunks ». Typiquement, chaque chunk fait entre 200 et 500 mots. Pourquoi ? Parce qu’on ne veut pas récupérer un document entier de 50 pages pour répondre à une question précise. Juste le ou les paragraphes pertinents.
Étape 3 : Transformation en vecteurs (embedding) : Chaque morceau de texte est transformé en une représentation mathématique, un vecteur de nombres. Ce vecteur capture le sens du texte, pas juste ses mots. On appelle ça un « embedding ». (On explique ça en détail dans la section suivante.)
Étape 4 : Stockage dans une base de données vectorielle : Tous ces vecteurs sont stockés dans une base de données spéciale, optimisée pour trouver rapidement les vecteurs les plus similaires entre eux. C’est la « base de données vectorielle » ou vector database.
Phase 2 : La requête pour répondre à une question
Maintenant qu’on a la bibliothèque prête, voici ce qui se passe quand vous posez une question :
Étape 1 : Votre question est transformée en vecteur : La même opération d’embedding est appliquée à votre question. Elle devient un vecteur.
Étape 2 : Recherche des morceaux les plus pertinents : La base de données vectorielle compare votre vecteur-question avec tous les vecteurs-documents stockés, et retourne les 3 à 10 morceaux les plus proches sémantiquement. C’est la « retrieval » ou récupération.
Étape 3 : Injection du contexte dans le prompt : Ces morceaux pertinents sont injectés dans la conversation envoyée au modèle de langage. En gros, on dit au LLM : « Voici des extraits de documents qui pourraient t’aider. En t’appuyant sur ces informations, réponds à la question. »
Étape 4 : Génération de la réponse : Le LLM génère sa réponse en s’appuyant sur les informations contextuelles qui lui ont été fournies. Il peut citer ses sources, indiquer d’où vient l’information, et répondre avec des données vérifiables plutôt que des extrapolations.
💡 Le terme RAG décrit exactement ces deux étapes : Récupération + augmentée par le contexte + génération de la réponse. Simple, non ?
Les embeddings et la recherche vectorielle
L’étape la plus mystérieuse du RAG, c’est souvent la transformation de texte en vecteurs. Qu’est-ce qu’un embedding et pourquoi cette approche permet-elle de trouver des informations pertinentes même quand on ne cherche pas les mêmes mots ?
L’espace sémantique : les mots et leurs voisins
Un embedding, c’est une traduction du sens d’un texte en coordonnées dans un espace mathématique à très haute dimension. Ça semble abstrait, mais l’idée est intuitive : des textes qui parlent de la même chose ont des coordonnées proches. Des textes qui parlent de choses différentes ont des coordonnées éloignées.
Exemple concret : la phrase « le client a signalé un problème de facturation » et la phrase « il y a une erreur sur ma facture » n’ont aucun mot en commun. Mais leurs embeddings sont proches dans l’espace vectoriel, parce qu’elles parlent du même problème. Un moteur de recherche classique par mots-clés ne ferait pas le lien. Un système d’embeddings le fait naturellement.
🗺️ Analogie géographique : imaginez une carte où chaque texte est un point. Les textes sur la cuisine française sont groupés dans une zone. Les textes sur la cybersécurité dans une autre. Quand vous posez une question, vous créez un point sur cette carte, et le système récupère les points les plus proches, les textes les plus « proches » sémantiquement.
Les modèles d’embedding en 2026
Pour transformer un texte en vecteur, on utilise des modèles d’embedding spécialisés. En 2026, les plus utilisés sont :
- text-embedding-3 (OpenAI) : le plus populaire, excellent en multilangue dont le français.
- Cohere Embed v3 : très performant, optimisé pour les applications RAG en entreprise.
- BGE-M3 (open-source) : le meilleur modèle en français utilisable localement via Ollama.
- nomic-embed-text : léger, rapide, idéal pour les déploiements locaux à faible latence.
Les bases de données vectorielles
Stocker et comparer des millions de vecteurs requiert des bases de données spécialisées, très différentes des bases SQL traditionnelles. En 2026, les principales sont :
- Pinecone : service cloud, très facile à démarrer, le choix des startups.
- Milvus : open source, performant à grande échelle, idéal pour les entreprises.
- pgvector : extension PostgreSQL, parfait si vous utilisez déjà PostgreSQL.
- Chroma : open source, simple, idéal pour les prototypes.
- Weaviate : open source, supporte le multimodal (texte et images).
Exemples d’utilisation concrets en 2026
La théorie c’est bien. Mais voyons concrètement où le RAG est utilisé au quotidien et pourquoi ça change la donne.
💬 Chatbot de support client (cas d’usage n°1)
Une entreprise de logiciels a une documentation produit de 500 pages, une base de tickets anciens, et une FAQ interne. Sans RAG, leur chatbot donne des réponses génériques ou hors sujet. Avec RAG, le chatbot consulte en temps réel la documentation lors de chaque question. Un client demande : « Comment configurer l’API en mode sandbox ? », le système récupère les deux paragraphes pertinents de la doc technique et génère une réponse précise et à jour.
Résultat : moins d’escalades vers les agents humains, documentation toujours à jour sans réentraînement.
🏥 Assistant médical avec guidelines actualisées
Un hôpital connecte son système RAG aux dernières recommandations de la HAS (Haute Autorité de Santé) et aux recommandations internationales. Quand un médecin interroge l’assistant sur le protocole de traitement d’une pathologie rare, le système récupère les recommandations les plus récentes et les présente avec leurs sources citées. Le médecin peut vérifier l’origine de chaque affirmation.
⚠️ Important : même dans ce cas, l’IA RAG est un outil d’aide à la décision, pas un médecin. La validation humaine reste indispensable dans tous les domaines critiques.
⚖️ Assistant juridique avec accès aux textes de loi
Un cabinet d’avocats connecte son RAG aux bases Légifrance et EUR-Lex mises à jour quotidiennement. L’assistant peut répondre à des questions sur les nouvelles réglementations, citer le texte de loi exact, et indiquer sa date d’entrée en vigueur. Fini les réponses basées sur des textes abrogés que le modèle avait mémorisé lors de son entraînement.
🏢 Assistant RH interne
Une grande entreprise connecte son RAG à ses documents RH internes : convention collective, règlement intérieur, fiches de poste, politiques de congé, procédures… Un employé demande : « Combien de jours de congés pour un mariage ? » Le système récupère le paragraphe exact de la convention collective applicable et répond précisément, sans risque d’erreur d’interprétation.
📊 Analyse financière et reporting
Une entreprise connecte son RAG à ses rapports financiers trimestriels, ses budgets et ses projections. Les analystes peuvent poser des questions en langage naturel « Quel était le chiffre d’affaires de la division Europe au Q3 2025 ? » et obtenir une réponse extraite directement des documents financiers, avec la source citée.
| Secteur | Source de données RAG | Bénéfice clé |
| Support client | Documentation produit, FAQ, tickets résolus | Réponses précises et sourcées |
| Médical | Recommandations HAS, publications scientifiques | Recommandations à jour, sources citables |
| Juridique | Légifrance, EUR-Lex, jurisprudences | Textes actuels, références exactes |
| RH | Convention collective, politiques internes | Réponses fiables sans interprétation |
| Finance | Rapports, budgets, données marché temps réel | Analyse factuellement ancrée |
| E-commerce | Catalogue, prix, stocks, avis clients | Recommandations dynamiques et exactes |
RAG vs Fine-tuning : deux approches complémentaires
Quand on veut adapter un LLM à un domaine spécifique, deux grandes approches s’affrontent souvent dans les discussions techniques : le RAG et le fine-tuning. Ce ne sont pas des concurrents — ce sont des outils différents pour des problèmes différents.
📌 Fine-tuning : Réentraîner partiellement un modèle IA sur un ensemble de données spécifiques pour qu’il adopte un style, des connaissances ou des comportements particuliers. Analogie : apprendre à un employé un nouveau domaine en lui faisant lire des centaines de livres et en l’évaluant régulièrement.
| Critère | RAG | Fine-tuning |
| Mise à jour des données | ✅ Instantanée (modifiez la base) | ❌ Nécessite un réentraînement |
| Coût | ✅ Modéré (stockage + API) | ❌ Élevé (GPU, temps, expertise) |
| Transparence / sources | ✅ Cite ses sources vérifiables | ❌ Opaque (mémorisé) |
| Qualité sur données spécifiques | ✅ Très bonne | ✅ Excellente (après entraînement) |
| Contrôle des données sensibles | ✅ Données restent dans votre infra | ⚠️ Données intégrées au modèle |
| Connaissances privées/internes | ✅ Oui, immédiatement | ✅ Oui, mais avec délai |
| Style et ton personnalisé | ⚠️ Limité (via prompt) | ✅ Excellent |
| Raisonnement de domaine profond | ⚠️ Dépend de la qualité du retrieval | ✅ Très intégré |
| Complexité de mise en œuvre | ✅ Accessible avec bons outils | ❌ Requiert expertise ML |
| Idéal pour… | Données changeantes, docs internes | Style, ton, connaissances très stables |
En pratique, la combinaison des deux approches donne souvent les meilleurs résultats : un modèle fine-tuné pour maîtriser le ton et le style de votre entreprise, augmenté d’un RAG pour l’accès aux données actualisées. La plupart des déploiements IA d’entreprise sérieux en 2026 utilisent les deux de concert.
Les outils RAG disponibles en 2026
La bonne nouvelle : construire un système RAG n’est plus réservé aux équipes avec des dizaines d’ingénieurs IA. L’écosystème d’outils a considérablement mûri. Voici un aperçu des principaux outils selon votre niveau technique.
🔧 Pour les développeurs : Les frameworks d’orchestration
- LangChain : le framework le plus populaire pour construire des pipelines RAG en Python. Très complet, riche en connecteurs pour les sources de données et les LLMs.
- LlamaIndex : spécialement optimisé pour l’indexation de documents et le RAG. Excellent pour les cas d’usage avec beaucoup de documents structurés.
- Haystack (deepset) : framework open source européen, fort en production enterprise, bon support du français.
🎨 Pour les non-développeurs : Les interfaces no-code
- Dify (dify.ai) : interface drag-and-drop pour créer des applications RAG sur ses propres documents. Utilisable sans une seule ligne de code.
- Flowise (flowiseai.com) : similaire à Dify, open source, déployable en local pour les entreprises soucieuses de confidentialité.
- Mistral Le Chat Entreprise : solution française avec RAG intégré sur vos documents, conforme RGPD.
- Microsoft 365 Copilot : RAG intégré sur toute votre suite Microsoft (emails, Teams, SharePoint, OneDrive).
- Notion AI : RAG sur l’ensemble de votre espace de travail Notion.
🚀 Pour tester le RAG sur vos propres documents en 5 minutes, sans coder : téléchargez Dify, créez une application de type « Chatbot avec base de connaissances », uploadez vos PDFs ou documents, et posez des questions. C’est vraiment aussi simple que ça pour une première expérimentation.
8. Les limites et les pièges à éviter
Le RAG est puissant, mais il n’est pas magique. Voici les limites réelles et les erreurs les plus courantes qui font que des systèmes RAG mal construits déçoivent.
⚠️ Limite 1 : La qualité des données en entrée
C’est la règle d’or du RAG : garbage in, garbage out. Si vos documents sources sont mal rédigés, obsolètes, contradictoires ou mal formatés, votre RAG produira des réponses de mauvaise qualité. Avant de construire un RAG, le travail de nettoyage et d’organisation des documents sources est crucial et souvent sous-estimé.
⚠️ Limite 2 : Le découpage (chunking) est une science
Comment vous découpez vos documents a un impact considérable sur la qualité de récupération. Des morceaux de texte trop petits perdent le contexte. Des morceaux de texte trop grands noient l’information pertinente dans du texte non pertinent. Le bon découpage dépend de la nature des documents, et il n’y a pas de réglage universel.
⚠️ Limite 3 : Le RAG ne supprime pas les hallucinations à 100%
Une réduction de 40-70% des hallucinations, c’est excellent. Mais pas zéro. Un LLM peut encore « inventer » des détails même quand il a accès à des documents pertinents surtout si les documents sont ambigus ou si la question est posée de façon imprécise. Il faut toujours valider les réponses critiques.
⚠️ Limite 4 : La latence s’ajoute
Chaque requête RAG implique une étape supplémentaire : la recherche dans la base vectorielle. Sur des bases de données bien optimisées, cette étape prend quelques dizaines de millisecondes. Mais sur des bases mal configurées ou très volumineuses, ça peut ralentir sensiblement les réponses.
⚠️ Limite 5 : Les données privées méritent une attention particulière
Si vous construisez un RAG sur des données sensibles (données médicales, documents juridiques confidentiels, informations financières), assurez-vous que votre architecture garantit que ces données ne transitent pas par des services cloud non sécurisés. Des solutions on-premise ou des services certifiés (comme Mistral AI ou des solutions souveraines) sont à privilégier dans ces cas.
L’évolution du RAG en 2026 : ce qui est en train de changer
Le RAG tel qu’on vient de le décrire, c’est le RAG « classique » ou « naïf ». La recherche et les entreprises ont beaucoup innové depuis 2020, et plusieurs approches plus avancées sont en plein essor.
Self-RAG : Le modèle qui décide quand chercher
Dans le RAG classique, le système cherche toujours dans la base de documents, même quand ce n’est pas nécessaire. Dans le Self-RAG, le modèle décide lui-même s’il a besoin de récupérer des informations ou s’il peut répondre directement. Si vous demandez « Quelle est la capitale de la France ? », le Self-RAG répond « Paris » sans déclencher de recherche. Si vous demandez « Quel est le prix actuel de votre produit X ? », là il cherche.
Agentic RAG : L’IA qui orchestre plusieurs recherches
Dans les applications d’agents IA (voir notre article sur les agents IA), le RAG est utilisé de façon dynamique : l’agent peut décider de consulter plusieurs bases de données différentes, reformuler sa requête si les premiers résultats ne sont pas satisfaisants, et combiner des informations de sources multiples. C’est le RAG multi-étapes, particulièrement puissant pour les questions complexes.
Multimodal RAG : Images, tableaux et PDF complexes
Les premiers systèmes RAG ne traitaient que du texte. En 2026, les RAG multimodaux peuvent indexer et récupérer des informations dans des images, des schémas, des tableaux, des graphiques et des présentations. Un assistant pourra bientôt répondre à « Montre-moi le graphique des ventes Q3 dans le rapport annuel » en récupérant directement l’image pertinente.
RAPTOR : Hiérarchie et résumés
RAPTOR est une architecture RAG avancée qui crée une structure hiérarchique dans la base de connaissances : en plus des chunks individuels, elle génère automatiquement des résumés à plusieurs niveaux de granularité (paragraphe, section, document entier). La récupération peut ainsi s’adapter à la nature de la question, chercher dans les détails ou dans les grandes lignes selon ce qui est pertinent.
🔮 Tendance 2026-2027 : la convergence entre RAG et agents IA autonomes. Les futurs assistants IA ne cherchent plus dans une base statique de documents, ils explorent dynamiquement le web, vos outils internes et des bases de données en temps réel, décident de la stratégie de recherche, et combinent les informations de multiples sources pour construire des réponses complexes et nuancées. C’est le RAG tel qu’il existera demain.
Récapitulatif : les 5 choses essentielles à retenir
| # | Ce qu’il faut retenir |
| 1 | Le RAG connecte un LLM à une base de connaissances externe, lui permettant de répondre avec des infos récentes et spécifiques au lieu de se fier uniquement à sa mémoire d’entraînement. |
| 2 | Il fonctionne en 2 phases : indexation des documents (une fois) + récupération des passages pertinents à chaque question. |
| 3 | Les embeddings transforment le texte en nombres qui capturent le sens, permettant de trouver des documents pertinents même avec des mots différents. |
| 4 | Le RAG réduit les hallucinations de 40-70% et permet de citer des sources vérifiables, un avantage majeur pour les usages professionnels. |
| 5 | Des outils no-code comme Dify ou Flowise permettent de créer un RAG sur ses documents en moins d’une heure, sans coder. |
Et vous, avez-vous déjà expérimenté avec le RAG ?
Le RAG est l’une de ces technologies qui semble abstraite jusqu’au moment où vous l’essayez sur vos propres documents et où vous réalisez concrètement ce qu’elle change.
🔸 Avez-vous déjà été victime d’une hallucination d’IA dans un contexte professionnel ? Une réponse fausse présentée avec confiance qui vous a posé problème ? Racontez-nous en commentaire, sans nommer de modèle si vous préférez.
🔸 La transparence des sources est l’un des grands avantages du RAG sur les LLMs classiques. Est-ce que cela changerait votre niveau de confiance envers un assistant IA si il vous montrait systématiquement d’où vient chaque information ? Ou faites-vous globalement confiance aux IA sans vérifier les sources ?
Partagez votre expérience en commentaire. Et si cet article vous a aidé à comprendre quelque chose qui vous semblait flou, dites-le nous, c’est exactement l’objectif de notre rubrique Décryptage IA.






