Tech-Connect Tech-Connect est un site web proposant des actualités, des tutoriels, des astuces et un forum dans le domaine technologique, informatique, science, télécommunications, mobile, tablette, windows, mac os, linux, opensource, android et IOS.
Tech-Connect Tech-Connect est un site web proposant des actualités, des tutoriels, des astuces et un forum dans le domaine technologique, informatique, science, télécommunications, mobile, tablette, windows, mac os, linux, opensource, android et IOS. 
Pourquoi tout le monde se met soudain à faire tourner des IA chez soi
Il y a deux ans, faire tourner un modèle de langage sans passer par OpenAI, Google ou Anthropic relevait du bricolage de geek chevronné, des heures de configuration Python, des dépendances qui ne s’installaient jamais correctement, et des résultats décevants comparés à ChatGPT.
En 2026, le paysage a complètement changé. L’IA locale, c’est-à-dire faire tourner un modèle d’intelligence artificielle directement sur votre ordinateur, sans connexion à un serveur distant, est devenue une pratique grand public. Et la raison est limpide : la confidentialité.
Quand vous tapez une question dans ChatGPT, Claude ou Gemini, votre texte voyage jusqu’à des serveurs distants, où il est traité, parfois conservé, parfois utilisé pour améliorer les modèles futurs. Pour un usage quotidien banal, ce n’est pas dramatique. Mais si vous travaillez sur un contrat confidentiel, un rapport médical, des données financières sensibles, ou simplement si vous tenez à votre vie privée par principe, l’idée que rien ne quitte votre machine devient extrêmement attrayante.
C’est exactement ce que permettent les outils que nous allons comparer aujourd’hui. Votre propre ChatGPT privé, gratuit, fonctionnel hors-ligne, et dont absolument rien ne part sur Internet.
Les bases : comment fonctionne une IA en local ?
Avant de comparer les outils, clarifions quelques notions essentielles pour les lecteurs qui découvrent ce monde.
Qu’est-ce qu’un LLM, et comment peut-il tourner sur votre PC ?
Un LLM (Large Language Model, grand modèle de langage) est le type d’IA qui fait fonctionner ChatGPT, Claude ou Gemini. Ce sont des réseaux de neurones entraînés sur d’immenses quantités de texte, capables de comprendre le langage naturel et de générer des réponses cohérentes.
Les modèles propriétaires comme GPT-5.5 ou Claude Opus 4.8 tournent sur d’immenses centres de données. Mais il existe aussi des modèles open source : Llama (Meta), Mistral (la startup française), Qwen (Alibaba), Gemma (Google), DeepSeek, dont les poids (les paramètres entraînés) sont publiquement téléchargeables. Ce sont ces modèles que vous pouvez faire tourner chez vous.
La quantification : la clé pour faire tenir une IA géante sur un petit ordinateur
Un modèle de langage performant peut contenir plusieurs dizaines de milliards de paramètres. Stockés dans leur format d’origine (32 bits par paramètre), ces modèles peuvent peser plusieurs centaines de gigaoctets, bien trop pour un ordinateur personnel.
La solution s’appelle la quantification : on réduit la précision numérique de chaque paramètre (de 32 bits à 8, 5 ou même 4 bits), ce qui diminue drastiquement la taille du modèle tout en préservant l’essentiel de ses capacités. Un modèle quantifié en Q4 (4 bits) pèse environ 4 à 8 fois moins que sa version originale, pour une perte de qualité généralement très limitée.
Le format de fichier standard pour ces modèles quantifiés s’appelle GGUF, popularisé par le projet open source llama.cpp. C’est ce format que la quasi-totalité des outils de cet article utilisent en coulisses.
CPU, GPU et RAM : ce qui détermine vos performances
Trois éléments matériels déterminent ce que vous pouvez faire tourner et à quelle vitesse :
- La RAM (mémoire vive) : pour faire tourner un modèle sur le processeur (CPU) uniquement.
- La VRAM (mémoire vidéo, sur votre carte graphique) : si vous avez un GPU dédié NVIDIA, AMD, ou une puce Apple Silicon, le modèle peut s’y charger pour une vitesse bien supérieure.
- Le processeur lui-même : un CPU récent avec support AVX2 (Intel 10e génération et plus, AMD Ryzen 5000+) accélère significativement l’inférence sur CPU.
La règle fondamentale est simple : plus le modèle est grand, plus il faut de mémoire. Un modèle 7B (7 milliards de paramètres) quantifié en Q4 occupe environ 4 Go. Un modèle 70B en Q4 nécessite environ 40 Go.
Tableau comparatif rapide : les 4 outils en un coup d’œil
| Outil | Facilité d’utilisation | Fonctionnalités avancées | Consommation de ressources | Public cible | Note globale |
|---|---|---|---|---|---|
| Ollama | 9/10 (Ligne de commande simplifiée) | 7/10 (Peu d’interface native) | Légère (Très bien optimisé) | Développeurs, intégrateurs, adeptes du terminal | 8,5/10 |
| LM Studio | 9/10 (Interface graphique claire) | 8/10 (Sélection aisée de modèles) | Moyenne (Interface un peu lourde) | Grand public, créateurs de contenu, curieux | 8,5/10 |
| AnythingLLM | 8/10 (Configuration guidée) | 9/10 (RAG et gestion de documents) | Moyenne | Professionnels analysant des documents privés | 8/10 |
| LocalAI | 5/10 (Nécessite Docker / Terminal) | 10/10 (Alternative complète aux API OpenAI) | Variable (Dépend de la configuration) | Développeurs confirmés, administrateurs système | 7,5/10 |
Maintenant, entrons dans le détail de chacun parce qu’un tableau ne dit jamais toute l’histoire.
🦙 Ollama : Le standard de facto pour les développeurs
Ce qu’il est devenu
Ollama est devenu l’un des outils les plus populaires pour le déploiement local de LLM, en particulier parmi les développeurs qui apprécient son interface en ligne de commande et son efficacité. Construit sur llama.cpp, il offre un excellent débit de tokens par seconde avec une gestion intelligente de la mémoire et une accélération GPU efficace pour NVIDIA (CUDA), Apple Silicon (Metal) et AMD (ROCm).
L’installation et la prise en main
C’est probablement la plus grande force d’Ollama : sa simplicité radicale.
# Linux / Mac
curl -fsSL https://ollama.ai/install.sh | sh
# Windows : télécharger l'installeur sur ollama.com
Une fois installé, faire tourner un modèle se résume à une seule commande :
ollama run llama3.1
Ollama télécharge le modèle et ouvre un chat directement dans le terminal. C’est tout. Pas de configuration de pilotes, pas de gestion manuelle de dépendances Python, Ollama fait le travail à votre place.
L’écosystème qui fait toute la différence
Ce qui distingue vraiment Ollama, c’est l’écosystème qui s’est construit autour. Son API REST compatible OpenAI, exposée sur localhost:11434, permet de l’intégrer facilement dans n’importe quelle application. La compatibilité avec le format OpenAI signifie que la plupart des outils existants fonctionnent directement avec Ollama en changeant simplement l’URL de base, remplacez api.openai.com par localhost:11434 dans votre code, et c’est terminé.
Cette compatibilité a engendré tout un écosystème de surcouches :
- Open WebUI : une interface graphique web complète, pour ceux qui veulent une expérience type ChatGPT par-dessus Ollama.
- Continue.dev : intégration dans VS Code et JetBrains pour le codage assisté.
- Dify, Flowise, AnythingLLM : des dizaines de projets open source listent Ollama comme infrastructure de premier choix.
Les chiffres clés
- Plus de 200 modèles prêts à l’emploi sur ollama.com/library.
- Support multimodal pour les modèles vision (LLaVA, Llama 3.2 Vision).
- Licence MIT open source, dépôt GitHub public.
- Possibilité de charger plusieurs modèles simultanément en mémoire (via les variables
OLLAMA_NUM_PARALLELetOLLAMA_MAX_LOADED_MODELS), utile pour router entre un petit modèle rapide pour la classification et un grand modèle pour la génération dans le même pipeline.
Pour qui c’est fait
Ollama est utile si vous êtes à l’aise avec un terminal. Beaucoup de gens l’utilisent comme un « service en arrière-plan » qu’ils oublient une fois qu’il fonctionne. Si vous construisez des logiciels autour de l’inférence locale, l’approche runtime/API d’Ollama peut sembler plus simple que les alternatives.
Limite à connaître : par défaut, Ollama écoute uniquement sur 127.0.0.1:11434 (localhost). Pour le rendre accessible sur votre réseau local, il faut configurer OLLAMA_HOST=0.0.0.0:11434 et dans ce cas, pensez impérativement à sécuriser l’accès avec un reverse proxy et une authentification.
🖥️ LM Studio : L’interface graphique qui démocratise l’IA locale
La philosophie de l’outil
LM Studio est une application bureau pour faire tourner des LLM en local avec une interface graphique. Elle se concentre sur la commodité : trouver des modèles, les télécharger, basculer entre eux, discuter, et éventuellement lancer un serveur local pour que d’autres outils puissent l’appeler.
Contrairement à Ollama qui fonctionne en ligne de commande, LM Studio propose une interface graphique complète : navigateur de modèles intégré, chat visuel, paramètres ajustables via des curseurs. Vous n’avez jamais besoin de toucher un terminal.
Ce qui le rend particulièrement adapté aux débutants
LM Studio a précisément été conçu pour démocratiser l’IA locale auprès des non-techniciens. Le navigateur de modèles recherche directement sur Hugging Face, la plus grande plateforme communautaire de modèles d’IA, ce qui rend la découverte de nouveaux modèles particulièrement fluide.
Concrètement, LM Studio supporte aussi le chargement de fichiers PDF, TXT et Word pour les analyser directement dans la conversation. Pour les documents courts, le modèle lit l’intégralité du contenu. Pour les documents longs, LM Studio active automatiquement un système RAG qui extrait uniquement les passages pertinents évitant ainsi de saturer la fenêtre de contexte du modèle. Pour charger un document, utilisez l’icône de pièce jointe dans la barre de saisie, ou glissez-déposez directement le fichier.
C’est particulièrement utile pour analyser des contrats sans rien envoyer dans le cloud.
La configuration minimale
LM Studio nécessite au minimum 8 Go de RAM, 10 Go d’espace disque, et un processeur supportant AVX2 (CPU postérieur à 2013). Côté système d’exploitation : Windows 10/11, macOS 12+, et Ubuntu 20.04+.
Pour une expérience confortable, comptez plutôt 16 Go de RAM, 50 Go de stockage, et un GPU avec 6 Go de VRAM minimum.
Le détail technique qui change la donne sur Mac
LM Studio supporte nativement le format MLX d’Apple, en plus du format GGUF universel. Sur les puces Apple Silicon (M1, M2, M3, M4), MLX peut être significativement plus rapide que GGUF, parce qu’il est spécifiquement optimisé pour l’architecture mémoire unifiée d’Apple. C’est un avantage net que LM Studio a sur Ollama pour les utilisateurs Mac.
Sur les machines sans GPU dédié, LM Studio dépasse souvent Ollama grâce à ses capacités de déchargement GPU ou offloading Vulkan.
La limite à connaître
Ollama est un logiciel libre sous licence MIT avec un dépôt GitHub public. LM Studio est un logiciel gratuit propriétaire, son code source n’est pas public. Pour les utilisateurs ou organisations qui exigent une transparence totale et un audit possible du code, c’est une distinction importante.
LM Studio ne supporte pas non plus le streaming d’appels d’outils ni des fonctionnalités avancées comme l’invocation de fonctions parallèle, un point à connaître si vous envisagez de construire des agents IA sophistiqués.
Pour qui c’est fait
LM Studio est idéal pour les débutants au déploiement local de LLM, les utilisateurs qui préfèrent les interfaces graphiques aux outils en ligne de commande, ceux qui ont du matériel peu puissant (surtout avec des GPU intégrés), et quiconque veut une expérience utilisateur professionnelle soignée sans toucher un terminal.
📚 AnythingLLM : Le champion du RAG et des documents privés
Ce qui le distingue fondamentalement
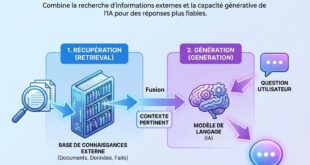
AnythingLLM n’est pas simplement un outil pour discuter avec un modèle. Sa spécialité, c’est le RAG : Retrieval-Augmented Generation, ou génération augmentée par récupération.
Comprendre le RAG, pour les non-initiés
Voici le problème que le RAG résout : un LLM, même très puissant, ne connaît que ce qu’il a appris pendant son entraînement. Il ne sait rien de vos documents personnels, de vos rapports d’entreprise, de votre contrat de location, ou de la documentation interne de votre boîte.
Le RAG fonctionne en trois étapes :
- Indexation : vos documents (PDF, Word, fichiers texte…) sont découpés en fragments, puis transformés en représentations mathématiques (des « vecteurs ») qui capturent leur sens.
- Récupération : quand vous posez une question, le système identifie les fragments de vos documents les plus pertinents pour y répondre.
- Génération : ces fragments pertinents sont injectés dans le prompt envoyé au modèle, qui génère sa réponse en s’appuyant sur ce contenu spécifique.
Le résultat : le modèle peut répondre précisément sur le contenu de vos propres documents sans avoir été entraîné sur eux, et sans que ces documents quittent jamais votre machine.
Les fonctionnalités qui en découlent
- Gestion de bibliothèques de documents organisées par dossiers/projets.
- Compatible avec plusieurs moteurs d’inférence en arrière-plan : il peut utiliser Ollama, LM Studio, ou ses propres modèles intégrés en arrière plan.
- Espaces de travail (workspaces) qui isolent différents contextes documentaires : pratique si vous gérez plusieurs clients ou plusieurs projets
- Agents intégrés capables d’effectuer des recherches web ou d’exécuter des actions définies.
Pourquoi c’est l’outil des professionnels avec des documents sensibles
Vous avez un contrat NDA à analyser ? Un rapport interne à résumer ? Une base de connaissances d’entreprise entière à interroger ? AnythingLLM est conçu précisément pour ce cas d’usage. C’est un choix particulièrement pertinent pour les avocats, les consultants, les chercheurs, ou toute profession manipulant une grande quantité de documents confidentiels qui ne devraient jamais transiter vers un service cloud.
La configuration
AnythingLLM nécessite une configuration guidée plus poussée que LM Studio. Il faut connecter un moteur d’inférence (souvent Ollama), configurer une base vectorielle pour le RAG (les options incluent LanceDB intégré par défaut, ou des solutions plus avancées comme Chroma ou Pinecone), et paramétrer les workspaces. La consommation de ressources est moyenne, dépendant fortement du moteur d’inférence choisi en arrière-plan.
Pour qui c’est fait
Les professionnels ayant besoin d’analyser des documents privés de façon répétée et structurée, pas seulement de discuter avec une IA générale.
🐳 LocalAI : Le couteau suisse pour les administrateurs systèmes
Sa vraie nature
LocalAI se positionne comme une stack IA complète, allant bien au-delà de la simple génération de texte. Elle supporte des applications IA multimodales incluant texte, image, et audio.
L’architecture qui justifie sa complexité
LocalAI inclut :
- LocalAI Core : les API texte, image, audio et vision.
- LocalAGI : pour construire des agents autonomes.
- LocalRecall : pour la recherche sémantique.
- Capacités d’inférence distribuée P2P : permettant de répartir la charge de calcul sur plusieurs machines.
- Grammaires contraintes pour forcer des sorties structurées précises (très utile pour les intégrations programmatiques).
LocalAI fournit un remplacement direct des API OpenAI, supportant tous les endpoints OpenAI standards plus des fonctionnalités supplémentaires. C’est l’outil le plus flexible et le plus complet de cette comparaison mais cette flexibilité a un prix en termes de complexité de mise en place.
Pourquoi c’est plus complexe à installer
Contrairement à Ollama ou LM Studio qui s’installent en quelques minutes, LocalAI nécessite généralement Docker et une configuration manuelle des conteneurs. Pour les administrateurs systèmes et développeurs confirmés, ce n’est pas un obstacle. Pour un débutant, ça représente une barrière d’entrée réelle.
# Exemple d'installation via Docker
docker run -p 8080:8080 --name local-ai -ti localai/localai:latest
Quand choisir LocalAI plutôt que les alternatives
Selon les analyses comparatives disponibles : LocalAI offre la plus grande flexibilité grâce à sa compatibilité API OpenAI et son support multi-modal, ce qui en fait un choix idéal pour les équipes qui migrent depuis des services cloud ou qui ont besoin de divers types de modèles (pas seulement du texte).
Pour qui c’est fait
Les développeurs confirmés et les administrateurs systèmes qui ont besoin d’une infrastructure d’inférence complète, multimodale, et qui acceptent l’investissement initial en temps de configuration pour obtenir une flexibilité maximale.
Et les autres outils qui méritent une mention
Le marché ne se limite pas à ces quatre outils. Voici quelques alternatives sérieuses selon des besoins spécifiques.
vLLM : Pour la performance pure en production
vLLM adopte une architecture fondamentalement différente, basée sur PyTorch avec des optimisations CUDA de bas niveau. Sur GPU NVIDIA, vLLM surpasse systématiquement Ollama et LM Studio grâce à ses optimisations CUDA. L’écart se creuse davantage en mode multi-utilisateurs, où le continuous batching (traitement par lots continu) de vLLM permet de maintenir un débit élevé même avec de nombreuses requêtes simultanées.
C’est l’outil de choix pour les déploiements de production à haute charge, mais sa configuration est nettement plus exigeante que celle d’Ollama ou LM Studio. Il est généralement recommandé d’utiliser LM Studio pour les tests et le prototypage local, puis de déployer vers vLLM ou LocalAI pour la fiabilité en production.
Jan : Le client bureau open source à l’esthétique soignée
Jan est un client pour bureau avec une interface particulièrement soignée, entièrement open source. Si la transparence du code est un critère décisif pour vous (contrairement à LM Studio qui est propriétaire), Jan est une excellente alternative à explorer. Il combine une interface graphique conviviale avec un code source entièrement auditable.
Llamafile : Pour la portabilité maximale
Llamafile mérite une mention pour son approche unique : un seul fichier binaire exécutable, sans installation requise. Idéal si vous voulez transporter un modèle sur une clé USB et le faire tourner sur n’importe quel ordinateur sans laisser de trace d’installation.
Configurations matérielles : ce que vous pouvez vraiment faire tourner
Voici un tableau pratique qui résume ce que différentes configurations matérielles permettent de faire tourner confortablement.
| Configuration | Modèles supportés | Performance attendue |
|---|---|---|
| 8 Go RAM, pas de GPU | Phi-3 Mini, Gemma 2B | Utilisable, mais lent (~8 tokens/s) |
| 16 Go RAM, GPU 6 Go VRAM (GTX 1060) | Mistral 7B Q4, Llama 3 8B Q4 | Correcte (~20-25 tokens/s) |
| MacBook Pro M2, 16 Go RAM unifiée | Llama 3.1 8B | Confortable (~25 tokens/s) |
| 32 Go RAM, RTX 3080 10 Go | Mistral 7B, Llama 3 8B, CodeLlama 13B Q4 | Bonne (~40-45 tokens/s) |
| 64 Go RAM, RTX 4090 24 Go | Llama 3 70B Q4, Mixtral 8x7B | Excellente |
| 2× RTX 3090 (48 Go VRAM combinés) | Llama 3.3 70B en Q4 | Confortable en multi-GPU |
Note pratique : pour un usage quotidien de rédaction, de résumé de documents, ou de codage assisté, un modèle dans la gamme 7B à 16B (Mistral Small 3.1, DeepSeek Coder V2 16B, Qwen2.5 Coder 7B) offre déjà un excellent rapport qualité/ressources. Réservez les modèles 70B aux machines équipées de GPU haut de gamme ou d’au moins 64 Go de RAM.
Les modèles open source à connaître en 2026
Le choix de l’outil n’est que la moitié de l’équation. Voici les modèles les plus pertinents à faire tourner selon vos besoins :
- Llama 3.3 70B (Meta) : le meilleur open source toutes catégories, mais nécessite 40+ Go de VRAM ou 64 Go de RAM en CPU.
- Mistral Small 3.1 (Mistral AI, France) : excellent rapport qualité/taille, 24B paramètres, tourne sur 16 Go RAM.
- DeepSeek Coder V2 : considéré par plusieurs benchmarks comme supérieur à GPT-4 pour le code ; la version 16B est accessible avec 16 Go RAM.
- Qwen2.5 Coder 7B (Alibaba) : plus léger, excellent pour la complétion de code au quotidien.
- Phi-3.5 Mini (Microsoft, 3,8B paramètres) : une qualité surprenante pour sa taille minuscule, idéal sur machines très limitées.
Arthur Mensch, PDG de Mistral AI, soulignait lors du Paris AI Summit 2026 : « L’efficacité de l’inférence locale a fait des progrès spectaculaires. Des modèles qui nécessitaient un cluster il y a 18 mois tournent maintenant sur un simple laptop. »
Comment choisir : la synthèse pratique
Pour résumer toute cette comparaison en quelques recommandations concrètes :
🎯 Vous êtes développeur, vous voulez scripter et intégrer l’IA dans vos applications → Ollama. Son API compatible OpenAI et son écosystème riche (Open WebUI, Continue.dev, LangChain) en font le choix le plus polyvalent pour construire quelque chose autour.
🎯 Vous découvrez l’IA locale, vous voulez une interface visuelle sans toucher un terminal → LM Studio. Navigateur de modèles intégré, chat graphique, et un excellent support pour les Mac via MLX.
🎯 Vous voulez interroger vos propres documents (contrats, rapports, bases de connaissances) → AnythingLLM. C’est le seul des quatre construit spécifiquement autour du RAG.
🎯 Vous êtes administrateur système, vous avez besoin d’une stack complète multimodale en production → LocalAI. Plus complexe à mettre en place, mais le plus complet et le plus flexible.
🎯 Vous avez une charge de production élevée avec de nombreux utilisateurs simultanés → Envisagez vLLM, qui surclasse les autres outils sur GPU NVIDIA en environnement multi-utilisateurs.
Astuce d’expert : beaucoup d’utilisateurs avancés combinent plusieurs outils. Une configuration courante : LM Studio pour explorer les modèles depuis Hugging Face confortablement, puis Ollama pour les intégrations en production une fois le modèle choisi. Les deux utilisent le même format GGUF, ce qui facilite grandement le passage de l’un à l’autre.
L’IA locale est-elle en train de devenir la norme ou restera-t-elle un marché de niche ?
Il y a deux ans, prédire que des centaines de milliers de particuliers feraient tourner des modèles d’IA performants sur leur ordinateur personnel aurait semblé optimiste. Aujourd’hui, c’est une réalité documentée, avec un écosystème logiciel mature, des modèles open source qui rivalisent sérieusement avec les versions commerciales sur de nombreuses tâches, et du matériel grand public (Mac Apple Silicon, cartes graphiques gaming) parfaitement capable de les faire tourner.
Ce qui me frappe dans cette évolution, c’est qu’elle répond à une tension de fond dans notre rapport à la technologie : nous voulons l’intelligence artificielle la plus puissante possible, mais nous sommes de plus en plus mal à l’aise avec l’idée de confier nos données les plus sensibles à des entreprises dont nous ne contrôlons ni les serveurs, ni les politiques de conservation, ni les futures conditions d’utilisation.
L’IA locale n’est pas qu’une question de coût (même si l’absence de facturation à l’usage compte). C’est une question de souveraineté numérique individuelle. Pouvoir dire avec certitude : ceci ne quitte jamais ma machine.
Cela dit, soyons honnêtes sur les limites actuelles. Les meilleurs modèles open source s’approchent des performances de GPT-5.5 et Claude Opus 4.8 sur de nombreuses tâches mais « s’approchent » n’est pas « égalent ». Pour les tâches les plus complexes de raisonnement, d’analyse fine, ou de génération créative de très haute qualité, les modèles propriétaires de pointe gardent généralement une avance.
La question qui se pose, je crois, n’est pas de savoir si l’IA locale va remplacer les services cloud, elle ne le fera probablement pas entièrement. C’est plutôt de savoir comment ces deux mondes vont coexister : l’IA cloud pour les tâches qui exigent la puissance maximale, et l’IA locale pour tout ce qui touche à la confidentialité, à l’autonomie, et au contrôle total de ses propres données.
Faites-vous déjà tourner une IA en local sur votre machine ? Lequel de ces outils avez-vous testé, et qu’en avez-vous pensé ? Quelle est votre configuration matérielle, et quels modèles parvenez-vous à faire tourner confortablement ?
Partagez votre expérience dans les commentaires.